
Hello everyone,
In this article, I’d like to walk you through a few key steps for keeping your data secure and continuously monitored in Amazon S3 AWS’s very first object storage service, launched back in 2006. Out of more than 240 services today, why start with S3?
When you look back, some of the biggest data breaches have almost always been tied to misconfigurations: IAM roles and users with excessive permissions, security groups left too open to the internet, and S3 buckets that were exposed due to incorrect settings. None of these stem from the provider itself they are all user-side mistakes. That’s exactly why in this post, I’ll highlight a few things many already know, but framed both as a reminder and with a slightly fresh perspective.
Let’s first consider what happens if you don’t secure your S3 buckets properly. Most of the examples I’ll share here come from legitimate sources created for security research purposes. They’re meant only to broaden your perspective please don’t attempt to download or misuse the data.
If a bucket that’s supposed to be private is accidentally left open to the internet, and its contents get referenced in a snippet of code or through a static object, services like PublicWWW or Common Crawl will eventually pick it up. Some of the most well-known examples in this space are AWSEye and GrayhatWarfare, which catalog exposed S3 buckets and their contents.
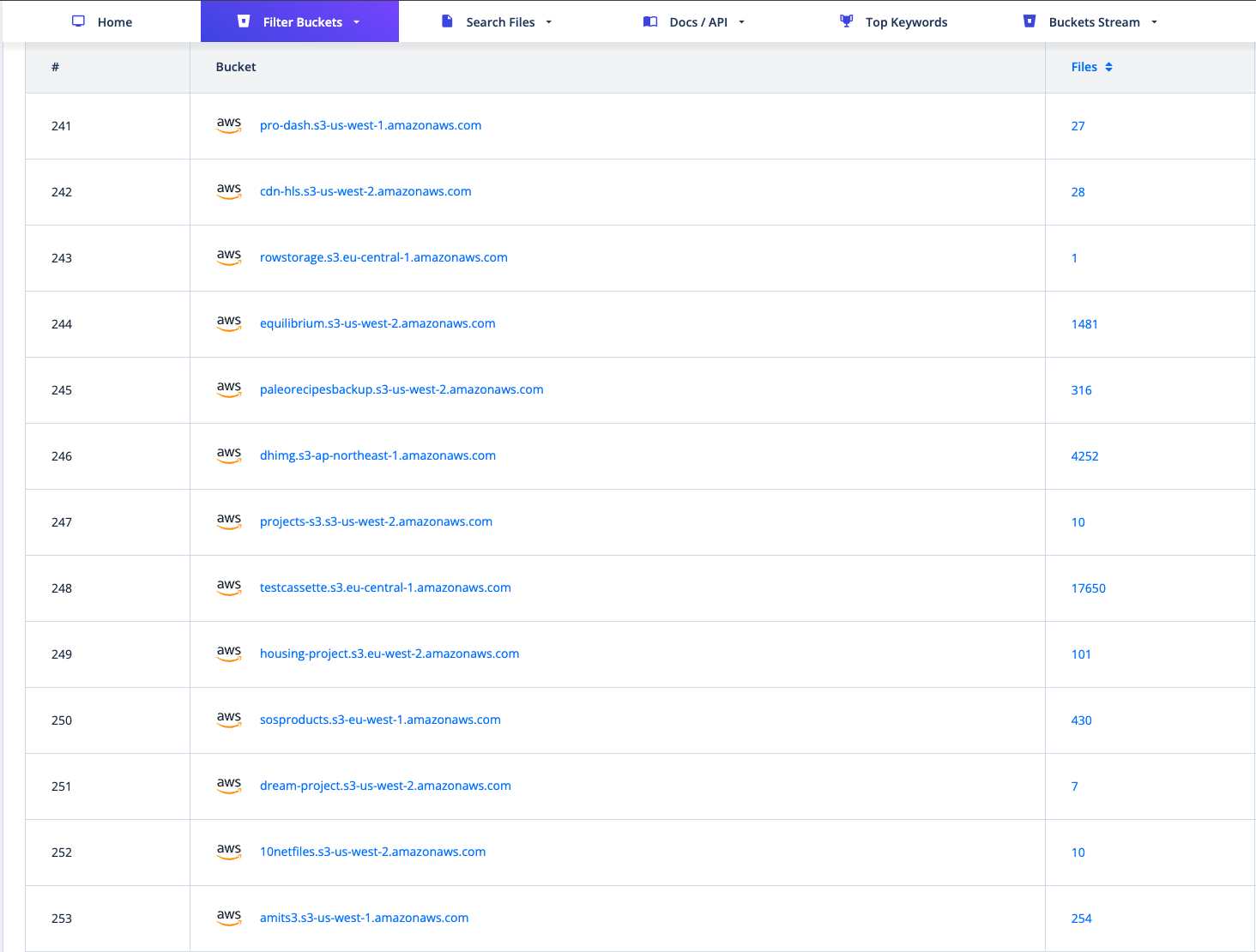
AWSEye:
-> https://awseye.com/resources?type=AWS::S3::Bucket
GrayhatWarfare:
-> https://buckets.grayhatwarfare.com/buckets?type=aws
If you’re curious about how these tools crawl data in the simplest way, you can take a look at the two GitHub repositories linked below:
-> https://github.com/clarketm/s3recon (Legacy method)
-> https://github.com/sa7mon/S3Scanner
Of course, crawling and public scanning cover a much wider range of techniques. My goal here isn’t to show every method or teach how it’s done it’s to show some real examples of what can be exposed when the right precautions aren’t taken. For example:
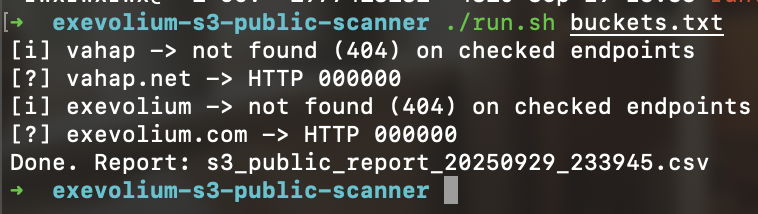
Now let’s get to the core of the discussion:
What steps can you take to improve S3 Bucket Security and S3 Cost Optimization?
AWS-Native Options:
1. S3 Object ACL (Legacy)
This is an authorization model that defines who has which permissions on a bucket or an object in S3. Every time you upload an object to S3, an ACL is automatically attached. By default, that ACL grants full control to the object owner (i.e., the account that uploaded it). With ACLs, you can assign READ, WRITE, or FULL_CONTROL on a file.
The types of principals you can grant permissions to include:
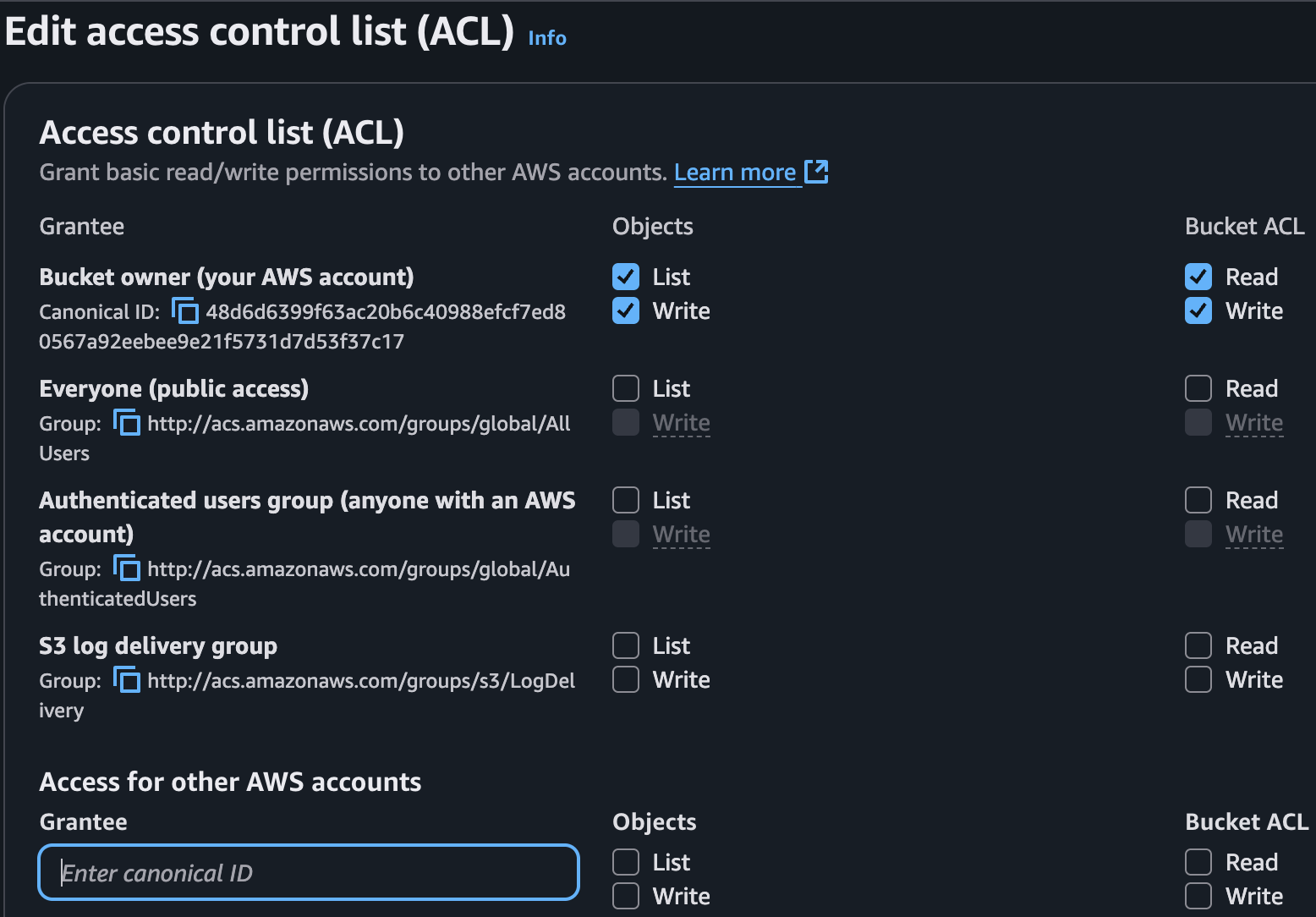
In this section, you can directly restrict access at the object or bucket level. However, since this approach is now considered legacy, AWS has been recommending the use of S3 Bucket Policies and IAM Policies for the past couple of years. If you do need to make a bucket publicly accessible (though you can also do this by simply marking the bucket or object as public), ACLs are still available. AWS continues to keep them active for backward compatibility.
2. S3 Public Access Settings
One of the most critical aspects of bucket security is whether an object or the entire bucket is left open to the public. If public access is enabled, it often results in directory listings being exposed and all objects becoming accessible.
When creating a bucket, if you’re not planning to use it for Static Website Hosting or don’t intend to make it publicly available, it’s best practice to leave the public access settings in their default state effectively blocking exposure from the start.

3. Bucket Versioning
If your application or a user accidentally deletes a file in S3, enabling versioning lets you roll back to a previous version of the object. Yes, versioning increases storage use (and cost), but you can control that with S3 Lifecycle rules for example, delete old versions after a set time or transition them to cheaper storage classes to reduce expense.
4. Encryption:
Since 2023, AWS requires that objects uploaded to S3 be encrypted by default and for good reason. That said, if you make a bucket or object public, encryption loses much of its practical value because in standard server-side encryption modes (SSE-S3 or SSE-KMS) AWS transparently decrypts objects when they’re downloaded. Still, encryption matters for real threat scenarios: it protects against theft of physical storage media and against unauthorized access within the AWS account if the user or role does not have decrypt permissions. Encryption also helps you meet regulatory requirements (HIPAA, PCI-DSS, etc.) and gives you better guarantees about data integrity: AWS does automatic checksum/validation during encryption flows, so tampering is detectable.
5. Object Lock:
Object Lock is useful when you need immutable storage for example, to satisfy legal retention requirements or to harden archives against ransomware. Object Lock works only on buckets where versioning is enabled. It enforces a write-once, read-many model: objects cannot be overwritten or deleted for the retention period you set (or indefinitely, if needed). Typical use cases include keeping financial records for a fixed number of years, preserving clinical data unchanged, or simply making sure backups and archives can’t be tampered with.
Object Lock has two modes:
Compliance mode: Strict: even the root user or accounts with special permissions cannot delete or overwrite objects until the retention period expires. Use this when you need legally enforceable immutability.
Governance mode: Prevents most users from deleting or modifying locked objects, but users with special privileges (e.g., those with s3:BypassGovernanceRetention) can still make changes. This mode is flexible for internal workflows where emergency overrides may be necessary.
6. MFA Delete Protection:
The MFA Delete feature adds an extra layer of security. Its purpose is to prevent critical deletions from happening without a second factor of verification. When enabled, it requires both valid IAM permissions and an MFA code in two key situations: disabling bucket versioning, and permanently deleting previous versions of objects. This protects against accidental deletions as well as malicious actions such as ransomware attacks. It’s worth noting that MFA Delete cannot be turned on from the AWS Console you’ll need to use the AWS CLI, SDK, or the S3 REST API to enable it.
7. S3 Server Access Logging:
Server Access Logging records every request made to objects within a bucket. By default, detailed logging is not enabled. But it becomes invaluable when you need audit trails for security reviews, want to understand abnormal or heavy traffic patterns, or need to meet compliance requirements.
When enabled, logs include details such as:
- Timestamp of the request
- The AWS account or IP address making the request
- Access method used (REST, SOAP, CLI, SDK, etc.)
- Which object was targeted
- Type of operation (GET, PUT, DELETE, LIST, etc.)
- Response code (200, 403, 404, and so on)
- Number of bytes transferred
8. AWS CloudTrail Data Events:
Unlike Server Access Logs, CloudTrail Data Events focus on API-level activity. They provide fine-grained visibility into who deleted, uploaded, or viewed an object. Data Events are disabled by default but can be turned on for stronger auditing, compliance, and security analysis. Without enabling them, AWS does not automatically log these object-level API calls in S3.
9. S3 Bucket Policies and IAM Access Analyzer for S3:
The IAM Access Analyzer for S3 helps you review and understand bucket access policies. It automatically checks whether a bucket is publicly accessible or if another AWS account has access. This eliminates the need to manually read through JSON policies line by line and provides a clear report of potential risks. Imagine dozens of buckets managed by different teams, and one of them temporarily sets a bucket to public but forgets to revert it. The analyzer will catch that misconfiguration and alert you, minimizing the chance of an accidental data exposure.
Meanwhile, an S3 Bucket Policy is a JSON-based document that directly defines access rules at the bucket level. With it, you can specify who can access what resource and how.
It’s often confused with IAM policies, so here’s the difference:
- IAM Policy permissions tied to a user or role (e.g., “this user can access this resource”).
- Bucket Policy permissions tied directly to a bucket (e.g., “this bucket can be accessed by these users”).
Why does it matter?
- Security: A poorly written policy can unintentionally expose your data to the internet.
- Centralized Management: Bucket-level rules apply across all objects in that bucket.
- Compliance: Ensures your security posture aligns with corporate policies and industry regulations.
10. Cross-Region Replication:
Amazon S3 is a region-based service. If a single Availability Zone (AZ) goes down, your data remains accessible, and AWS guarantees 11 nines of durability (99.999999999%). However, if an entire region were ever to become unavailable (which, to date, has never happened), access to your data could be impacted. That’s why enabling cross-region replication can be an important part of a disaster recovery strategy, ensuring copies of your data exist in another geographic location.
11. Amazon Macie:
Macie is a security service built on AI and machine learning to help protect the data you store in S3. Its primary purpose is to automatically detect and classify sensitive information, such as personally identifiable information (PII), financial records, or confidential business data. With Macie, identifying which files in your S3 buckets contain sensitive data becomes far easier, especially at scale. It’s a powerful tool, but also a relatively costly service so it’s worth reviewing the pricing model carefully before enabling it.
12. S3 Storage Lens:
S3 Storage Lens provides an organization-wide view of how your S3 buckets are being used across one or multiple AWS accounts. It gives insights into storage usage, activity trends, and potential areas for cost optimization. At the very least, I recommend turning on the free-tier dashboard, as it offers valuable visibility into your storage footprint without additional cost.
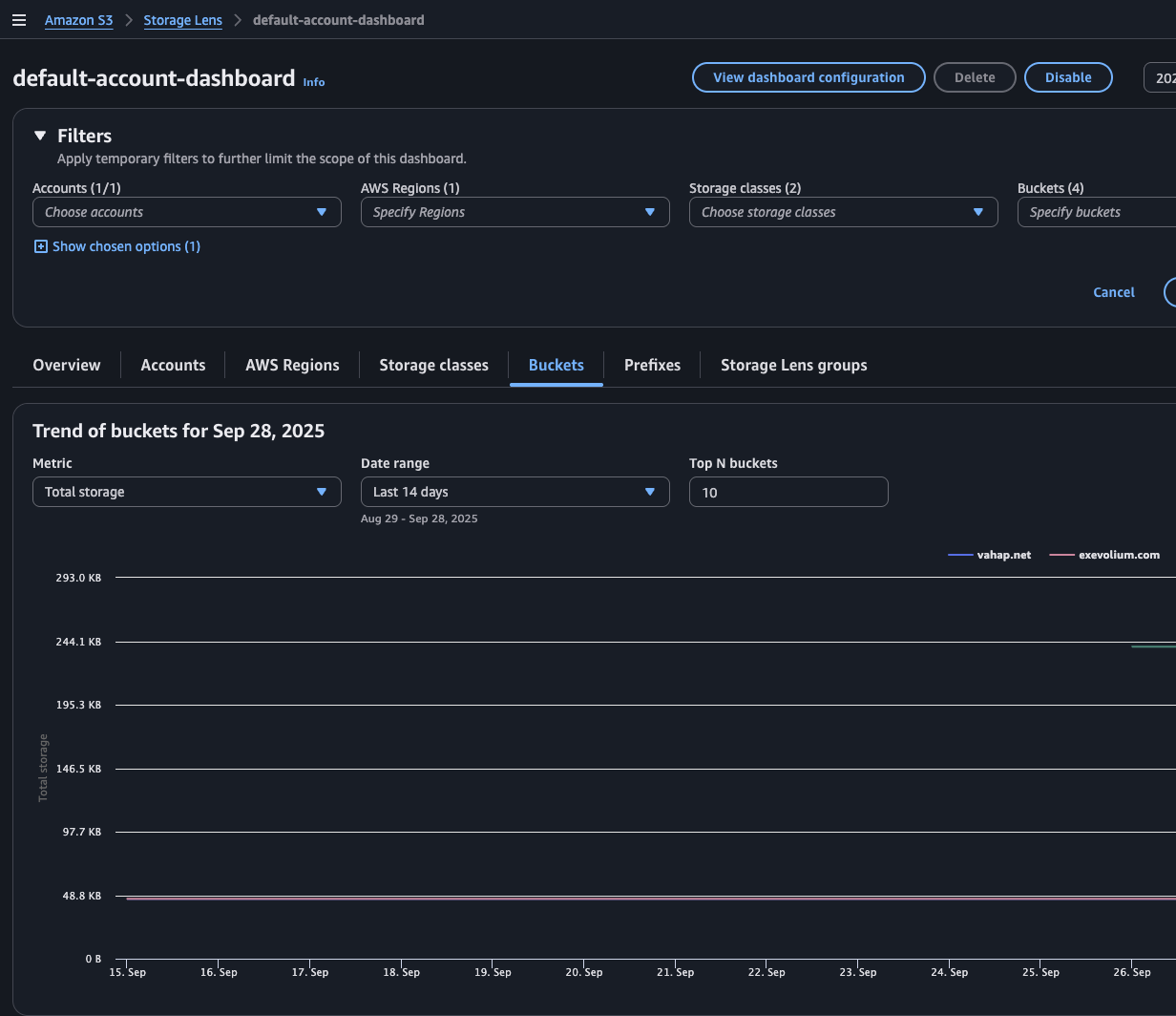
If your AWS environment is managed under an AWS Organization, you don’t need to enable S3 Storage Lens account by account. Instead, you can configure it centrally from the management account and generate dashboards that cover all linked accounts and buckets at once. This makes visibility and cost optimization much easier across a multi-account setup.
13. CloudWatch Alarms:
While CloudWatch alarms are often used to trigger other actions, in our scenario they’re especially useful for monitoring requests to your S3 buckets. Why does this matter? Because in AWS, even failed requests can generate costs.
For example, imagine you have a NetBackup server in Account A writing data to a bucket in Account B. If the bucket name or path is incorrect, the request will fail but AWS will still charge you for it. Setting up alarms helps you spot these mistakes early and avoid unnecessary charges.
You can also use alarms to notify you whenever an object is uploaded or deleted from a bucket, giving you real-time awareness of critical changes in your environment.
14. VPC Endpoint for S3:
When you upload data from a resource within your AWS account to S3, using an S3 VPC Endpoint ensures the traffic flows directly through the AWS network rather than over the public internet. As long as the transfer happens within the same region, this setup saves you from paying extra data transfer costs for sending or retrieving data from S3.
15. Lifecycle Manager:
One of the biggest cost drivers in Amazon S3 is storage classes. Let’s quickly refresh our memory:
- S3 Standard
- Price: ~0.023 USD / GB / month
- The go-to option for data you access frequently in daily operations. High durability and low latency make it the default choice.
- S3 Standard-IA (Infrequent Access)
- Price: ~0.0125 USD / GB / month (+ per-access fee)
- Best for data you don’t use often but still need quick access to — like backups or archived reports.
- S3 Intelligent-Tiering
- Price: ~0.023 USD / GB / month (plus a small monitoring fee of ~0.0025 USD per 1,000 objects)
- AWS automatically moves objects to cheaper tiers based on access patterns, saving you the trouble of manual planning.
- S3 Glacier
- Price: ~0.004 USD / GB / month
- A low-cost option for long-term archiving. Retrieval can take anywhere from a few minutes to several hours.
- S3 Glacier Deep Archive
- Price: ~0.00099 USD / GB / month
- The cheapest storage class available. Designed for data you rarely, if ever, need to access. Retrieval can take hours.
By carefully choosing the right storage class for each object and applying lifecycle policies, you can cut your S3 costs by half or more.
So, we’ve covered what you can do to improve security and cost optimization for your AWS S3 resources and also highlighted how, if overlooked, misconfigurations could make your data accessible to the wrong hands.
I hope these article help save you time.
References: